Cite this article as:
McRitchie, K. (2022). How to think about the astrology research program: An
essay considering emergent effects. Journal of Scientific Exploration, 36(4),
706-716. DOI: 10.31275/20222641. [PDF]
Highlights—A
review of recent astrological research and a meta-analysis show a methodical
program that is tackling problems and improving results in terms of
quantifiable correlations and effect sizes. The value of the program is not
just to test the truth of standard astrological taxonomies but to understand,
along with other disciplines, the process of how effects emerge from complex
systems.
Abstract—As
it has been shaped by improvements in its tools and methods, and by its
discourse with critics, I describe how the astrological research program has advanced
through three stages of modelling and design limitations. Single-factor tests
(for example, the many Sun-sign-only experiments that have been published) are
typically under-deterministic. Multi-factor tests, unless they are very well
designed, can easily become over-deterministic. Chart-matching tests have been
vulnerable to confirmation bias errors until the development of a machine-based,
whole-chart matching protocol that has objectively produced evidence of high
effect-sizes. A meta-analysis of recent results shows the rapid advancement and
how to further improve the results. The value of the program is not only to corroborate
the taxonomic counterfactuals of astrological “cookbooks,” but to extend their
explanatory reach by the comparison of astrological postulates and inferences
with philosophies in other disciplines in terms of quantifiable processes and
emergent effects.
Introduction
Quantitative research
in astrology did not begin in earnest until the mid-twentieth century and has depended
on statistical research tools and computational power to adequately look into
the claims of the astrology postulate. By the term astrology, I mean as a
definition, the study of the positions and motions of celestial bodies in
relation to the character of lives and events. By the term postulate, I refer mainly
to the applied principles and applied theory documented in astrological textbooks,
the so-called cookbooks. Some examples of modern cookbooks are: Sakoian
and Acker’s The Astrologer’s Handbook (1973); Richard B. Vaughn’s Astrology
in Modern Language (1985); and Margaret Hone’s The Modern Text Book of
Astrology (1978).
The word
astrology comes from the Greek (astr + logos) loosely meaning
“star word” or “star speech.” Modern cookbooks carry on the tradition from
antiquity of organizing astrological properties as a semantic taxonomy of
interpretations. Each planet’s position in the sky is
interpreted by the categories of: its sign; its diurnal house (a 12-fold frame
of reference affixed to the local horizon and meridian); and its aspects (its angular
distance to the other planets). For example, a cookbook-described position would
be for: Mars in Sagittarius; Mars in the Ninth House; and Mars opposite Moon (with
Mars and the Moon on opposite sides of the Earth, 180° apart). Astrology
presumes emergent effects from the consequential combinations of these astrological
factors.
Most astrological research
concerns Natal Astrology—the study of birth charts. A birth or natal
chart is a sky-map positioned on the birth of the individual, called the native,
as a microcosm at the relative center of the Solar System, and in the greater macrocosmic
sense, at the center of the universe. Hence, the native’s planets (including
the Sun and the Moon) are relative planets because they, in a fashion, move
around the native, as does the native’s universe. A natal chart is evaluated semantically for
the native’s potential characteristics and experiences, and how these are astrologically
influenced, mainly by day-to-day interactions with other natives—who represent parallel
universes or parallel worlds so to speak. There are other branches of astrology (deVore,
1947, p. 29) such as World or Mundane, that studies eclipses,
ingresses, and major planetary cycles with regard to populations. And there are
Horary and Electional, which study propensities at the moment of
a query, idea, or event (Horary), or seeks to optimize the time and
place for a specific event in the future (Electional).
The research
program can be understood in terms of what I will call three stages of experimental
complexity. I will introduce them briefly here before giving examples in
subsequent sections. The earliest stage, that first suggested quantifiable evidence
of astrological effects, relied on relatively simple single-factor experiments.
These consist of correlational tests of planetary features as a single factor and
the corresponding theoretical interpretations that might be categorized, for
example, under a single section in the cookbooks. Next came multi-factor experiments
that evaluate several chart factors in combination, postulated as a model or signature
of an observable feature of the natives who have it. Most recently, are whole-chart
automated simulations that evaluate all the combined factors in natal charts. All
three of these experimental methods have specific uses within the research
program.
The development of single-factor
and multi-factor protocols included identification of astronomical and
demographic artifacts that would confound the measurements of astrological effects.
The developed protocols include data randomization methods that generate neutral
control groups to evaluate significant correlations (Gauquelin, 1988; O’Neill,
1995; Ertel, 1995; Ruis, 2008; Tarvainen, 2012).
Single-factor experiments
The best-known examples
of single-factor experiments are the large-scale studies of eminent
professionals done by French researchers Michel and Françoise Gauquelin (1955,
1975). Guided by traditional interpretations, Michel Gauquelin initially tried
to correlate astrological properties (from the cookbooks) with the natal charts
of famous professionals whose timed birth data he could obtain. The main groups
tested were: athletes; actors; scientists; doctors; artists; writers; corporate
executives; military leaders; musicians; and politicians. When Gauquelin did
not immediately find any clear effects, he experimented by dividing the four diurnal
quadrants into finer slices of 36 and 18 sectors as well as the customary 12 Placidus
houses.
Gauquelin’s research
led to the discovery of what he called key-sectors, which are two slices
of sky within which he found that certain planets (Moon, Mars, Jupiter, or
Saturn) correlate significantly to attainment of eminence in their astrologically
associated professions. The data peaks of the key-sectors are located just after
rising above the eastern horizon and just after culmination at the upper meridian.
The inference of professional prominence due to the planetary placements in
these sectors became known as the eminence effect. Because achievement
in sports is measured exactingly and Gauquelin found the Mars key-sector sports
correlation to be especially strong, and because there is a constant supply of
young athletes to use as subjects, Gauquelin recommended that replication
experiments test eminent athletes for Mars in key-sectors.
The Mars-athletes
replication tests proved to be a battleground with many experiments conducted
and accusations of sampling bias from both sides over what qualified as professional
eminence (Ertel & Irving, 1996). The controversy has diminished, however, following
a critical study by Professor Suitbert Ertel (1988) that objectively ranked the
eminence of famous athletes in the entire sample that had accumulated (N
= 4291) by a frequency of 1 to 5 based on whether they were cited in five
sports reference books.
Ertel found that
the Mars-eminence effect diminishes for each lower rank of athletes in a near-linear
fashion. Compared to a randomized control group, the “monotonic trend with
ranked qualitative data” (p. 71) demonstrates a very low probability against
chance of p < 0.005 (where p < 0.05 is considered to be
significant in the social sciences). To show the size of this effect, Ertel calculates
Kendall’s Tau to determine effect size (ES
= 0.037) as the correlation coefficient of the ranks (where perfect correlation
is 1). This calculation indicates a quite weak effect, although this is not
surprising as it is the evaluation of a single astrological factor among the many
possibly related factors in a chart that could be contributors. The significance
of Ertel’s finding comes from the very low probability of the ordered ranks
occurring by chance: (N = 4291, p = 0.005, ES = 0.037).
Most astrological
experiments, however, do not measure ranked results as in Ertel’s example, and other
evaluations of effect-size (ES) would apply. Until recently, ES has not been included
in astrology studies (nor in most scientific studies) and it is proving to be a
highly useful metric, as I will show. There are various methods of calculating ES
and the one applicable for most astrological experiments (Currey, 2022) is the
Pearson product-moment correlation coefficient between pairs of variables, r
(Cohen, 1988, p. 75), where r = 1 is perfect correlation, as
used in the remaining examples of this article.
A more typical
design of a single-factor experiment is one by astrologer Paul Westran (2021).
Westran studied 1,300 romantic relationships of famous people (2,600 natal charts)
in terms of synastry—the mutual alignments between two natives’ charts. This
study looked for correlations between the starting time of a relationship or
marriage and the transit or secondary (day-for-a-year) progression aspects of
the Sun and Venus between the partners’ charts. The results show an extraordinarily high
significance for the Sun/Venus aspects that are traditionally conducive of intimate
relationships (conjunctions, trines, and oppositions) compared
to a control group of the same size (N = 5,200, p = 4.76 x 10-11, r = 0.09).
These examples give an idea of how single-factor experiments
can work to find a specific astrological value, thereby reducing ambiguity in
the result. But single-factors have limitations because they tend to require
very large samples and they ignore all the other factors in the natal charts
resulting in weak effect sizes. To say that any single factor must be
definitive in the lives of the natives who have it seems an extraordinary claim
considering that there are always other factors in a natal chart that can have somewhat
similar values and effects. Indeed, most professionals who have attained
eminence in their fields do not have their Gauquelin-correlated planet in
either of the two key-sectors. If we were to seriously consider emergent effects,
then we need to include other astrological factors that contribute to the
recipes of correlational outcomes. Indeed, we can typically find many
suggestions of such related combinations scattered among the single-factor
descriptions in the cookbooks.
It seems to me that
single-factor testing is susceptible to under-determination, meaning that
a single factor is not necessarily sufficient to evaluate an astrologically
significant effect. The listings in the cookbooks suggest that a multiplicity
of factors in any natal chart are assumed to converge, intersect, or otherwise blend
together to produce emergent results. Yet, this critical assumption has been
ignored by hundreds of single-factor experiments, including a disproportionate
number of Sun-sign only studies (e.g., Dean et. al., 2016; Helgertz & Scott, 2020). and Moon-phase only
studies (Marko, 2017), many of which have been done with unrealistic
expectations and have led to disappointing results (Houran & Bauer, 2022). The
evaluation of emergent effects would seem to entail an additional approach—a multi-factor
testing or some variation of multiple regression, and these are methods that the
research program also explores.
Multi-factor experiments
By relating, blending
together, and modelling some of the factors in a natal chart into what we might
call astrological signatures, multi-factor experiments overcome the
problem of under-determinism. This approach tries to identify tell-tale combinations
of natal chart factors that have either similar or antagonistic tendencies that
we would presume to amplify, diminish, or otherwise moderate a theme of given characteristics
in a native. To give a simple two-factor example observed by the Gauquelins, keysector
Mars positively correlates to athletic eminence and yet the Moon in a keysector
is antagonistic and negatively correlates to the athletic effect (Gauquelin, 1988,
p. 144). The Moon appears to moderate the Mars effect, which is consistent
with the astrological properties of the Moon. Many suggestions as to how some factors
moderate other factors and impose contingencies on interpretation as to what
may manifest are scattered throughout the cookbooks.
The problem with multifactor
testing is that it can easily suffer from nomological over-determination,
which is the opposite problem of single-factor testing. This is where there are
too many similar and potentially sufficient factors according to the documented
rules in the literature to easily sort out exactly which astrological features
are responsible for which experienced effects. A few authors have compiled interpretations
of combined chart factors, although such works are rare because of the semantic
complexity of blending the many potential factors in a chart. To help accomplish
this, the verbose descriptions typical of single-factor interpretations are
conceptually condensed to very brief statements. For example, in German
astrologer Reinhold Ebertin’s (1940) classic The Combination of Stellar
Influences, Ebertin lists single-factor and combined-factor descriptions with
just a few short phrases and keywords to be used as building blocks.
In view of the over-deterministic
limitations, a multi-factor experiment would try to identify a characteristic feature
of interest in a homogeneous sample of subjects and combine only a few
well-defined, appropriate descriptions from the cookbooks to test as a
hypothetical model of the feature. The modelling could include such common
manipulations as applying planetary “weights” where, for example, the Sun and
Moon are given more weight and the outer planets are given less weight. Planets
with astrological properties that suggest dominance in an effect can be tested
with more weight to better assess their contribution. Such treatments or interventions
of a sample would seem to have the best chance of corroborating and improving
the cookbooks. Of course, this is not to say that completely new theories cannot
be usefully tested and explained. Let me give some example studies of how multi-factor
modelling has been done.
As
written in virtually all astrology textbooks, Venus and the sign Libra, over which
it is said to “rule” (being the sign most consonant with the planet’s
characteristics), and Jupiter and its rulership sign Sagittarius, are
associated with judges. A multi-factor study modeled on these associations by British
astrologer Robert Currey (2021a, 2021b, 2022) tests the natal charts of 115
justices of the Supreme Court of the United States (SCOTUS) appointed since
1789. The frequency of astrological combinations of these two planets, whether
by occupying their own or each other’s sign or house, or by their astrological
conjunction, shows a significant correlation to the textbook theory (N =
115, p = 4 x 10-4,
r = 0.31). Currey’s test corrects a claim against astrology by author
Alexander Boxer (2020, pp. 86-89) that concluded from a single-factor test that
there was “no correlation” between any Sun sign and SCOTUS justices, including
Sun in Libra, which had been Boxer’s chosen astrological hypothesis.
Another multi-factor
study by Currey (2017) uses Eysenck’s Personality Inventory (EPI) and also corroborates
astrological theory. The model semantically matches the EPI trait words for Extroversion [E] and Neuroticism [N] to the corresponding keywords for the
astrological elements (Fire, Earth, Air, and Water) drawn from the texts of
well-known astrologer authors. The multi-factor keywords are from the interpretations
given for the positions of the Sun, Moon, and Ascendant, which are traditionally
the most personal chart factors and make a suitable model for such a test.
The results of Currey’s
EPI study show that participants who scored high in Extroversion [E+] and low
in Introversion [E-] were high in Fire signs and low in Earth signs (N =
216, p = 0.009, r = 0.16). Participants who scored high in
Emotional Stability [N-] and low in Neuroticism [N+] were high in Air signs and
low in Earth signs (N = 216, p = 0.007, r = 0.17). These
results corroborate the cookbook interpretations. Currey’s test uses original
data provided by Geoffrey Dean (1985a, 1985b, 1986), who had claimed that his
experiments showed no astrological correspondence to EPI results that are better
than chance.
A study by mathematician
Kyösti Tarvainen (2013) of professional mathematicians uses 25 natal chart factors
that do not require birth times (which were unavailable for the sample) that
are favorable to the profession based on a standard cookbook (Sakoian &
Acker, 1973). The factors are significantly more frequent in the mathematician
group than in a randomized control group (N = 2759, p = 0.03, r
= 0.04). The low effect size (r) of this result increases for the same factors
in a much smaller subgroup of only those individuals who had won a prestigious
prize in mathematics (N = 99, p = 0.04, r = 0.18).
Having some reliably
significant although modest results in multi-factor tests makes it possible to intervene
in the same tests by substituting various claimed astrological theories,
techniques, and settings to determine whether they fare better or worse against
the best evidence so far. A descriptive summary of such substitution tests done
by various researchers (Tarvainen, 2021a) includes comparisons of tropical
versus sidereal zodiacs (where the tropical zodiac, which is based on the
solstices and equinoxes is compared to the Lahiri ayanamsha sidereal
zodiac that is traditionally used in Indian/Jyotisha astrology). Other
comparison tests include: various diurnal house systems; sizes of orb settings
(the margins of influence near an alignment); various midpoint configurations; and
various synastry techniques. These evaluations are in the early stages but hold
promise as I will show by an example later.
Whole-chart matching experiments
To avoid the under-deterministic
limitations of single-factor experiments, and the over-deterministic excesses
of multi-factor experiments, some of the research in the post-Gauquelin era has been
drawn to whole-chart matching experiments. These tests do not discriminate any
specific traits or characteristics but have been used simply as a verification test
of whether astrology can work without describing how. Typically, these are blind
tests that challenge astrologers to match natal charts to the biographies or personality
test scores of their owners. Chart matching experiments have been touted as the
ideal test of astrology because: the subjects can be ordinary people; all
factors in the chart are used; there are no demographic or astronomical artifacts;
there is no need for control groups; and the statistical analysis is simple
(Godbout, 2020).
The first notable
blind matching tests were done between 1959 and 1970 by psychologist Vernon
Clark (1961, 1970). For example, one of his experiments tests the efforts of 50
professional astrologers and a control group of 20 psychologists and social
workers. All participants were asked to match the descriptions of 10
professionals with their charts, given the choice of the genuine chart and a
bogus chart for each. The control group successfully matched 50% of the sample,
as expected by chance. The astrologers matched 65%, which is significant (N
= 500, p = 1 x 10-4,
r = 0.17).
Despite
this promising beginning, serious researchers have been reluctant to do
chart-matching tests due to the organizational, logistical, and discomforting
issues of astrologers challenging their own colleagues. Typically, researchers have
preferred to quietly develop their own theories and evidence by working independently. Also, while matching tests may be
interesting as a game or a contest, they have not been regarded as adding explanatory
value. This is because the Vernon Clark protocol blends the astrological
interpretations of participants as an aggregate or a black-box result that
does not expose the fine-grained effective information (Wolchover, 2017)
on theory and problems where we think the emergence of astrological properties,
effects, and agency can be traced. The usual multi-factor models seemed to hold
more promise for analysis than whole-charts. The resulting state of affairs
left the door open for astrology critics who designed their own Vernon Clark tests,
chose the participants and informed them as they saw fit, did their own
analysis, and drew their own conclusions.
Like the earlier
Gauquelin tests of Mars and eminent athletes, chart-matching tests soon became
a battleground over questionable methods and published claims that astrologers
did not perform any better than chance (Carlson, 1985; McGrew & McFall,
1990; and Nanninga, 1996/97). However, unlike the Gauquelin controversy,
matching tests require neither control groups nor homogeneous samples. Consequently,
flaws in the tests are more clearly identifiable. Some of the counter-criticism
against the aforementioned tests include: samples that are too homogeneous to
differentiate (cherry picking); improper design and analysis (p-hacking); and discarding
potentially corroborating data (publication bias) (Ertel, 2009; Currey, 2011;
and McRitchie, 2009, 2014, 2016). In one study where the test data was published
(Carlson, 1985), re-analyses by Ertel (2009), who did the heavy lifting, and
Currey (2011), who made further refinements, claim to reverse the results as evidence
that supports astrology. Currey’s re-analysis found the results to favor the astrologer participants (N = 115, p = 0.037, r = 0.1). Ertel’s and Currey’s claims of positive results have remained unchallenged. For readers who are interested, the articles published by both sides of the chart-matching controversy are freely available and can be examined and judged in detail.
Having said that, chart-matching
tests have recently made an important advance. Astrology software and automated
protocols have been developed to make matching tests much bigger and
objectively more accurate. The latest evidence suggests that the previous controversies
may be moot.
Automated chart-matching
Of prominent
interest are the automated chart-matching tests of Canadian mathematician
Vincent Godbout (2020) that uses an expert astrology software system designed
for keyword analysis, called Mastro Expert, and a programmed utility he calls a
“Semantic Proximity Estimator” that is similar in function to a “machine
scientist” or a symbolic regression algorithm (Wood, 2022). Godbout’s regression
algorithm evaluates chart matches semantically in a blind protocol with samples
that are much larger than humans have a capacity to analyze. In principle, this
design approach would be the same as a multi-factor experiment except it tracks “all”
the factors in the sample charts and does not try to discriminate any signature
feature or characteristic that the subjects may share in common.
To make the
matches, the machine uses the possible instances of about 3,000 keywords drawn from
over 5,000 chart factors that Godbout sourced from the publications of 25 modern
international astrology cookbook authors (American, French, British, German,
and Canadian). By removing human limitations, the experiments surpass all
previous matching tests in terms of safety, size, and difficulty of challenge.
The automation also quashes the otherwise hard-to-falsify claim (Dean et. al.,
2016) that successful chart-matchings may be due to ESP ability.
In Godbout’s (2020,
2021) first automated chart-matching experiment, the machine had to match two separate
samples (experimental, N = 41 and verification, N = 32) of natal
charts of famous people by using characteristic keywords (in noun form) drawn from
the natives’ biographies sourced from Le Monde (Subtil and Rioux, 2011).
All the biographies were used for which accurately timed birth data could be obtained,
which provided the total study-sample of N = 73 out of the 100 subjects
listed in the source book. The only part of the protocol that requires human
involvement is the extraction of keywords from the biographies, which is done
blindly without knowledge of the astrological charts.
The matches are
evaluated by 8 binomial distributions that account not only for the correct identification
of a subject’s chart as the top-scoring choice but also for near misses where
the correct chart is within the top 2 choices, within the top 3 choices, and so
on up to the top 8 choices. Thus, for Godbout’s combined sample of 73 subjects,
the correct identification as the highest scoring choice has a probability against
chance expectancy of 1/73; within the top 2 it is 2/73; within the top 3 it is 3/73,
and so on to 8 places. In this manner, the 73 charts are matched against the 73
biographies to determine how many correct matches are found in each binomial bucket
of the top 8 choices. The machine identified the correct charts much more
frequently than chance expectancy for each bucket. For example (Godbout, 2021,
p. 38), the “worst result” was for bucket 2 with 2 expected but 9 observed (N
= 73, p = 1.73 x 10-4,
r = 0.42). The best result was for bucket 7 with 7 expected but 24 observed
(N = 73, p = 3.97 x 10-8,
r = 0.63).
Given
the high correlations of this original test to use as a benchmark, Godbout
(2020, 2021) ran replications within the same study to test interventions against
the astrological standards he used. This is the same approach mentioned earlier
in the substitutions studied by Tarvainen. The standards Godbout interfered
with are: standard orb settings based on the British Faculty of Astrological
Studies (Tompkins, 1989, p. 66); accurate birth times; major midpoints; and the
tropical zodiac. The substitution of the most widely-used non-tropical zodiac (Lahiri
ayanamsha) failed to achieve significance. The substitution of tighter than
standard orb settings, of rounded birthtimes, and of tests without midpoints
resulted in lowered significance. These results suggest not only that the tested
existing standards are good but that the method of experimental interventions in
whole-chart testing can provide evidence capable of extending and improving the
reach of astrological theory in detail.
What the research program looks
like
By entering the
walled garden of astrological research and regarding the work as a concerted
program of tested models, methods, and data, an overall view of the program begins
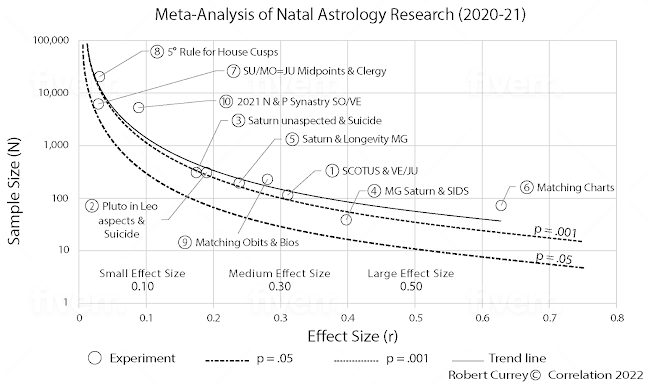
to take shape. Figure 1 is from a meta-analysis by Robert
Currey (2022) of experiments published between the years 2020 to 2022. It shows
a distinctive, logarithmic trend of relationships between sample size (N),
effect-size (r), and probability (p). Correlational results that
are above the lower dashed curve are greater than the threshold (alpha) of
statistical significance, p < 0.05. The uppermost curved solid line
is the regression trendline of the 10 research findings.
Figure 1. Meta-analysis of astrology research 2020-2021
with trendline (from Currey, 2022).
As the plot points
in the graph show, single-factor experiments (for example, Westran’s Sun/Venus synastry
study, Point 10), can produce very high probabilities given its large sample,
although the effect-size for a single factor out of the many available in a
natal chart is quite small. Multi-factor experiments (for example, Currey’s
SCOTUS study, Point 1) combine astrological factors and can produce stronger
effect-sizes, a result that begins to suggest emergent effects. But the
strongest evidence for emergent effects is from whole-chart matching experiments
(for example, Godbout’s automated tests, Point 6) that can produce both a high
probability and a large effect-size.
For some studies, the
classification of whether a test is single-factor or multi-factor is a bit loose
at this stage as astrology is a complex system, but for this meta-analysis, we
will consider that the single-factor tests are: 4, 5, 7, 8, and 10; the multi-factor
tests are: 1, 2, and 3, and the whole-chart tests are 6 and 9. See Table 1 for further
details.
Table 1. Details
of the Figure 1 meta-analysis (Currey, 2022). For the 10 studies: Mean r
= .24; Median r = .21
|
Author (Year)
|
Hypothesis
|
Factors
|
N
|
p
|
ES: r
|
|
④
Douglas (2021a)
|
Saturn
in MG Sectors & SIDS
|
single
|
38
|
0.007
|
0.40
|
|
⑤
Douglas (2021b)
|
Saturn
& Longevity MG
|
single
|
197
|
4 ´ 10-4
|
0.24
|
|
⑦
Tarvainen (2021a)
|
SU/MO=JU
Midpoints & Clergy
|
single
|
6,285
|
0.01
|
0.03
|
|
⑧
Tarvainen (2021b)
|
5°
Rule for Houses
|
single
|
20,394
|
4 ´ 10-7
|
0.03
|
|
⑩
Westran (2021)
|
N
& P Synastry SU/VE
|
single
|
5,200
|
4.76 x 10-11
|
0.09
|
|
①
Currey (2021b)
|
SCOTUS
& VE/JU theme
|
multi
|
115
|
4 ´ 10-4
|
0.31
|
|
②
Currey (2021c)
|
Pluto
in Leo aspects & Suicide
|
multi
|
311
|
4 ´ 10-4
|
0.19
|
|
③
Currey (2021c)
|
Saturn
unaspected & Suicide
|
multi
|
311
|
0.001
|
0.18
|
|
⑥
Godbout (2020)
|
Automated
Matching Charts
|
whole
|
73
|
3.9 ´ 10-8
|
0.63
|
|
⑨
Tarvainen (2021c)
|
Matching
Obituaries & Bios
|
whole
|
233
|
1 ´ 10-5
|
0.28
|
Key: JU =
Jupiter; MG = Michel Gauquelin data; MO = Moon; N = Natal; P = Progressed; SIDS
= sudden infant death syndrome; SU = Sun; VE = Venus.
As a practical aid for
research design, Currey’s meta-analysis helps estimate the minimum sample sizes
needed for tests to have a reasonable chance of significance. This is useful
because data privacy laws have made accurately timed birth data very difficult
to obtain. For well-designed tests, Currey’s (2022, p. 55) recommended minimum
sample sizes—based on Cohen’s (1988) guidelines—are: for single-factor tests,
350 subjects (600 to 1000 for Sun-sign experiments); for multi-factor tests, 70
subjects; and for whole-chart tests 25 subjects. To ensure safety, most studies
will need enough subjects for two separate tests: an experimental test and a verification
test. This would double the size of Currey’s recommendations, as the data would
be randomly distributed between the two tests.
Seeing that the use
of combined cookbook factors appears to boost effect-size, one must wonder whether,
given a sufficient number of properly interpreted factors in whole-chart
experiments, effect-size could not extend all the way to 1 (perfect
correlation) with every chart tested making a correct first-choice match. There
is room for improvement in several areas. Godbout (2020, p. 24) identifies three
types of losses that are sources of experimental “entropy”: the loss of
accuracy when recording birthtimes; deficiencies and inconsistencies in the described
personality traits present in the biographies or personality test scores; and deficiencies
in astrological semantics.
In regard to reducing
informational losses and building more complete semantic models, Godbout’s already
impressive best effect-size of 0.63 does not include the positions of planets
in the diurnal houses that are the entire basis of the Gauquelin findings. This
is because Godbout (p. 14) could not establish a consensus among authors on
keywords for houses. The lack of consensus suggests that eminence effects (or skills
and aptitudes in general) and the departments of life to which they apply (as
houses are described in the older texts) have been mistakenly “updated” by modern
humanistic authors, such as Dane Rudhyar (1936) who have tried to psychologize everything
in a chart. Research can possibly correct this. Additionally, there is the enormous
task of testing and evaluating the plethora of “advanced” and esoteric techniques
that astrologers have dreamt up over the centuries, as we find in most astrology
software programs as options. The question is what, if anything, these techniques
contribute to the accuracy of astrological interpretations.
Discussion
In my opinion, the
greater goal of astrological research, beyond demonstrating its validity, is to
improve its applications and to explain theory. Astrological textbooks cover theory
descriptions but provide few details on process. To use the
cooking metaphor, the cookbooks are heavy on ingredients (properties), but do
not say enough about proportional recipes (combinations) or the relational steps
and settings for how the cooking (evaluation) is actually done.
In a more
trans-disciplinary approach, it may seem odd but astrology is not the only
discipline to use the recipe metaphor to describe the analysis of complex
systems and emergent effects. For example, computer scientist Judea Pearl
(Pearl & Mackenzie, 2018, p. 12) maps out what he calls an inference
engine that tests presumed knowledge with “recipes” to evaluate emergent
effects.
In my
interpretation of Pearl’s inference engine, existing knowledge assumptions (theories)
that have been modeled by scientists (with relevant single-factor or multi-factor
constituents) are subjected to a query of interest. Different recipes or
estimands for answering the query are then applied to critically transform
the model (as experimental interventions or treatments). The model is then tested
with input data to obtain a statistical estimation of emergent effects.
The resultant evaluations are then used to improve the starting assumptions and
further modelling. In a more simplified description of eliciting inferences,
Pearl (pp. 130-131) describes piecemeal interventions as “wiggling” one piece
(either a supposed source A, or a supposed mediator B) while holding the other
pieces steady and observing the emergent effects on C.
Although Pearl is
concerned mainly with tracing causal effects and mediators, the same reasoning
would seem to apply to firming up correlational effects in astrology. Presumably,
there are no causal astrological effects in the accepted physical sense but
there are inferred correlational effects. As explained by the early modern leader
of scientific empiricism, Francis Bacon (1857, p. 351), “The last rule (which
has always been held by the wiser astrologers) is that there is no fatal
necessity in the stars; but that they rather incline than compel.” Note
carefully that Bacon’s rule suggests that astrological inclinations are
actually beyond empirical observation. They are inferred tendencies that the
native might or might not follow. The native may buck the influences that other
natives—other worlds or other parallel universes, so to speak—may have on their
own world.
Regardless of what
the native does, astrology must assume emergent patterns of prevailing trends that
are responsible for its statistical inferences and its truth values. The
researched truths depend on the statistical models not only to correlate astrological
properties but also to correlate the so-called astrological influences,
as neither of these effects can be empirically perceived but are rather
inferred from the models and the evidence.[10] As astrology presumes to already know a
great deal about its own trend-inducing configurations, as documented in the
cookbooks, the research effort is partly a question of how to isolate and corroborate
the complex, interrelated taxonomies from the statistical data as evidence.
Astrology research must deal with problems of
over-determination and under-determination because its keyword constituents are
difficult to disentangle from the keyword aggregations where the correlational
results are observed to emerge. The same burden of isolating constituent
properties also appears in other disciplines of inference. If one were to think
more analytically about the problem of constituents, each descriptive keyword
of the applied theory is what astrologers call a potential, which means
a potential instance or potential fact, or more precisely, a counterfactual
property that, in some combination with other counterfactual properties, might
or might not manifest—but tends to manifest—certain emergent properties
as resulting instances. This analysis is consistent with Oxford theoretical physicist
Chiara Marletto’s (2021) definition of counterfactuals as “meta-statements
about what can or cannot be made to happen” within the limitations of natural
laws.
In a natural,
biological context, combinations of counterfactual properties are what Marletto
(p. 13) calls “abstract catalysts.” These catalysts, she explains, are
naturally selected “recipes” that codify copyable facts about the environment
as constituents of a generative process that gives lifeforms an entropy-resistant
“resilience” capable of “keeping themselves in existence” well beyond the rapidly
degrading impermanence of non-living things. The recipes represent a sort of
informational “knowledge” in the sense that it is reproducible and transferable. In my interpretation, this knowledge of counterfactual
would-have-been adaptations results in emergent characteristics that can operate
well below the threshold of consciousness, as Marletto says this knowledge “does
not have to be known to anyone.”
In a laboratory research
context, Pearl (pp. 9-10) describes the language of counterfactuals as the “building
blocks of scientific thought” that reaches beyond empiricism by inference. He
says that “whereas regularities can be observed, counterfactuals can only be
imagined,” and yet they are “not products of whimsy but reflect the very
structure of our world model.” We make “very reliable and reproducible
judgments all the time about what might be or what might have been.” Pearl even
extends the building blocks concept to say that the “algorithmization of
counterfactuals invites thinking machines to … participate in this (until now)
uniquely human way of thinking about the world.” Like human minds, a machine
can represent possible counterfactual worlds and “compute the closest one” (p.
268). This almost sounds like a description of Godbout’s chart-matching machine
that selects the nearest biography (closest world) among given natal charts
according to a symbolic regression algorithm (machine scientist) that is modeled
by the semantic taxonomies and rules of astrological knowledge.
These
trans-disciplinary considerations of emergent effects suggest that the process
of creating and applying replicable, resilient counterfactual knowledge, as selectively modeled in codes or recipes, is available not only within the internal processes
of organisms but also within human minds and thinking machines. As a comparable
counterfactual process, it is hard to deny the resilience of astrological knowledge
as it has been semantically codified, thought about, copied, and taxonomically refined
with high fidelity since the beginnings of recorded history.
Implications and applications
The implication
of astrological research, with its body of counterfactual knowledge, has always
been that it reaches beyond the empirical limits of sense perception and yet
the knowledge is intrinsic and discoverable by inferences from data. Thus, it
is unrelated to psychic perceptions, given that ESP can be defined as not the
result of any means we know of (Phillipson, 2000, p. 139-140). This makes me
wonder what could be learned by comparing astrological thinking with psychic
thinking as we would expect a difference.
Following Godbout’s
machine findings, it seems likely that astrological cookbooks are poised for a
more complete knowledge transfer to automated systems that, assisted by machine
scientists, can enable more accurate astrological descriptions of potential and
emergent worlds than is humanly possible. For comparison, it might be
interesting to match psychic abilities with such machines, for example, in
blind tests to identify issues of character and events.
Conclusion
Effect-size is
the new wrinkle in astrological research. There is no question that well-informed
critics have played a crucial role in bringing attention to this important
metric and, along with their other statistical contributions, it is serving to
sharpen the skills and shape the program of the small community of responsible researchers.
With the help of effect-size metrics and meta-analysis, the contours of
effective information in astrology are beginning to emerge. In this present
article, I have considered the research program to be loosely organized in
terms of single-factor, multi-factor, and whole-chart methods that each provide
different powers of study.
At first, whole-chart
methods had seemed like a game played against astrologers by their critics—until
it became automated by a machine capable of semantically analyzing nearly all
the important factors in many natal charts at once, a feat that is well beyond
human limitations. As the implications are far-reaching for in-depth research
into the nature of astrological factors as semantically interpreted potentials,
Godbout’s findings especially need independent replication.
The Solar System planets
are the astrological symbols and emissaries of connections between each native’s
world of the people and events that truly influence their lives. The research
suggests how to infer semantic properties by the emergence of distinctive
patterns of character, behavior, and experience. The astrological design of experimental
models and their corroboration with cookbook interpretations—which are in
effect a corpus of its theory—cannot be a scientific mystery as it uses the same
methods of inferring evidence of truth values.
Notes
Acknowledgments
I am grateful to:
Vincent Godbout; Robert Currey; Kyösti Tarvainen; Peter Marko; and the anonymous
JSE reviewers for their comments and suggestions.
References cited
Bacon, F. (1857). The Works of Francis Bacon: The
advancement of learning, Vol. 4, De Augmentis. Longman, Brown, and Co.
London.
Boxer, A. (2020). A Scheme of Heaven: The history of
astrology and the search for our destiny in data. W. W. Norton &
Company.
Carlson, S. (1985). A double-blind test of astrology. Nature,
318:419-425.
Clark, V. (1961). Experimental astrology. In Search,
Winter/Spring: 102-112.
Clark, V. (1970). An investigation of the validity and
reliability of the astrological technique. Aquarian Agent, 1(October):2-3.
Cohen, J, (1988), Statistical Power Analysis for the
Behavioral Sciences: Second Edition. Lawrence Erlbaum Assocs. Publishers,
NJ.
Currey, R. (2011). Shawn Carlson’s double-blind astrology
experiment: U-turn in Carlson’s astrology test? Correlation, 27(2):7-33.
Currey, R. (2017). Can extraversion [E] and neuroticism [N]
as defined by Eysenck match the four astrological elements? Correlation,
31(1):5-33.
Currey, R. (2021a). Testing astrology based on practice
rather than theory: A system for extracting themes in birth charts. Correlation,
33(2):65-75.
Currey, R. (2021b) Justice for the Supreme Court: Delving
beyond a Sun Sign Test of 114 Justices. Correlation, 33(2):77-86.
Currey, R. (2021c). The New York suicide study: Reconsidered
and reversed. Correlation, 34(1):31-57.
Currey, R. (2022). Meta-analysis of recent advances in natal
astrology using a universal effect-size. Correlation, 34(2):43-55.
Dean, G. (1985a). Can astrology predict E and N? 1:
Individual factors. Correlation, 5(1):3-17.
Dean, G. (1985b). Can astrology predict E and N? 2: The whole
chart. Correlation, 5(2):2-24.
Dean, G. (1986). Can astrology predict E and N? 3: Discussion
and further research. Correlation, 6(2):7-52. Includes meta-analyses of
astrological studies.
Dean, G., Mather, A., Nias, D., & Smit, R. (2016). Tests
of Astrology: A Critical Review of Hundreds of Studies. AinO Publications.
deVore, N. (1947). Encyclopedia of Astrology. Littlefield,
Adams & Co. Totowa, NJ.
Douglas, G. (2021a). Replication of Ertel’s result on Sudden
Inftant Death Syndrome and Saturn in key Gauquelin Key sectors. Correlation,
33(2):87-94.
Douglas, G. (2021b) Human Longevity, the Gauquelin Effect and
Heliocentric Cycles. Correlation, 34(1):59-76.
Ebertin, R. (1940, Rev. ed. 1972). The Combination of
Stellar Influences. American Federation of Astrologers, Inc., Tempe,
Arizona.
Ertel, S. (1987). Further grading of eminence: planetary
correlations with musicians, painters, writers. Correlation, 7(1): 4-17.
Ertel, S. (1988). Raising the hurdle for the athletes’ Mars
Effect: Association co-varies with eminence. Journal of Scientific
Exploration, 2(1):53-82.
Ertel, S. (1995). Randomizations furnish precise chance
expectations. In M. Pottenger (Ed.), Astrological Research Methods, Vol. 1.
Seek It Publications.
Ertel, S. &
Irving, K. (1996). The Tenacious Mars Effect. Urania Trust, London.
Ertel, S. (2009). Appraisal of Shawn Carlson’s renowned
astrology tests. Journal of Scientific Exploration, 23(2):125-137.
Gauquelin, M. (1955). I’influence des Astres: Étude
critique et expérimentale. Éditions du Dauphin, Paris.
Gauquelin, M, (1975). Spheres of influence. Psychology
Today (Brit.), 7(October):22-27.
Gauquelin, M. (1988). Written in the Stars. The
Aquarian Press, Wellingborough UK.
Godbout, V. (2020). An automated matching test: Comparing
astrological charts with biographies. Correlation, 32(2):13-41.
Godbout, V. (2021). To use or not to use midpoints? Correlation,
33(2):35-48.
Helgertz, J., Scott, K. (2020). The validity of astrological
predictions on marriage and divorce: a longitudinal analysis of Swedish
register data. Genus 76(34).
Hone, M. E. (1968). The Modern Text Book of Astrology.
L. N. Fowler & Co. Ltd, Romford.
Houran, J. & Bauer, H. H. (2022). ‘Fringe Science’ – A
tautology, not pariah. Journal of Scientific Exploration, 36(2):
207-217.
Marko, P. J. (2017). The Lunar Effect Bibliography: A
categorized, annotated, and indexed list of publications on how the Moon
affects our lives. CreateSpace Independent Publishing Platform.
Marletto, C. (2021). The Science of Can and Can’t: A
physicist’s journey through the land of counterfactuals. Viking.
McGrew, J. H. & McFall, R. H. (1990). A Scientific
Inquiry into the Validity of Astrology. Journal of Scientific Exploration,
4(1):75-83.
McRitchie, K. (2004). Environmental Cosmology: Principles
and theory of natal astrology. Cognizance Books, Toronto.
McRitchie, K. (2006). Astrology and the social sciences:
looking inside the black box of astrology theory. Correlation, 24(1):5-20.
McRitchie, K. (2009). Support for astrology from the Carlson
double-blind experiment: Review of ‘A double-blind test of astrology.’ ISAR
International Astrologer, 40(2):33-38.
McRitchie, K. (2014). Cognitive bias in the McGrew and McFall
experiment: Review of “A scientific inquiry into the validity of astrology.” ISAR
International Astrologer, 41(1):31-37.
McRitchie, K. (2016). Clearing the logjam in astrological
research: Commentary on Geoffrey Dean and Ivan Kelly’s article “Is astrology
relevant to consciousness and psi?” Journal of Consciousness Studies,
23(9-10):153-179.
Nanninga, R.
(1996/97). The Astrotest: A tough match for astrologers. Correlation,
15(2):14-20.
O’Neill, M. (1995). Actual or Generated Control Groups. In M.
Pottenger (Ed.), Astrological Research Methods, Vol. 1, Seek It
Publications.
Pearl, J. &
Mackenzie, D. (2018). The Book of Why: The new science of cause and effect.
Basic Books, New York.
Phillipson, G. (2000). Astrology in the Year Zero.
Flare Publication, London.
Rosenthal, R. and DiMatteo, M.R. (2001). Meta-Analysis:
Recent Developments in Quantitative Methods for Literature Reviews. Annual
Review of Psychology, 52:59-82.
Rudhyar. D. (1936). The Astrology of Personality. Lucis
Publishing Company.
Ruis, J. (2008). Statistical analysis of the birth charts of
serial killers. Correlation, 25(2):7-36.
Sakoian, F. & Acker L. (1973). The Astrologer’s
Handbook. Collins Reference.
Subtil, M-P. & Rioux, D. (2011). Le Monde – Les grands
portraits. Éditions Les Arènes.
Tarvainen, K.
(2012). A test of overall validity of astrological statements in the handbook
by Sakoian and Acker. Correlation, 28(1):5-24.
Tarvainen, K.
(2013). Favorable astrological factors for mathematicians. Correlation,
29(1):39-51.
Tarvainen, K. (2021a).
Statistical studies have started to advance astrological techniques. Correlation,
33(2):55-64.
Tarvainen, K.
(2021b). Confirmation of Ptolemy’s 5-degree rule for Koch and Equal Houses. Correlation,
34(1):9-16,
Tarvainen, K.
(2021c). Guessing Aspects from interviews and obituaries. Correlation,
34(1):77-88.
Tompkins, S.
(1989). Aspects in Astrology. Elements Books.
Vaughn, R. B. (1985). Astrology in Modern Language.
CRCS Publications, Sebastopol, CA.
Westran, P. (2021). Astrology using progressed synastry in
1,300 public cases: A validation study. Correlation, 33(2):13-33.
Wolchover, N. (2017). A Theory of Reality as More Than the
Sum of Its Parts. Quanta Magazine.
https://www.quantamagazine.org/a-theory-of-reality-as-more-than-the-sum-of-its-parts-20170601/
Wood, C. (2022, May 10). Powerful “machine scientists”
distill the laws of physics from raw data. Quanta Magazine. https://www.quantamagazine.org/machine-scientists-distill-the-laws-of-physics-from-raw-data-20220510/